Representation learning has been hugely beneficial to the process of getting machine learning (ML) to do useful things with text. These useful things include getting better search results from a Google search, and synthesizing images given text prompts (such as done by models like DALL-E). Representation learning is about learning meaningful ways to mathematically represent input data. The power of representation learning is that a single ML model can often extract mathematical representations of an input (e.g. a sentence) which are useful for a great number of downstream tasks (e.g. doing a Google search, or using the sentence to condition DALL-E). Creating a good representation learning model may take considerable time and expertise to figure out what the model should actually be, and then significant time and resources to train it. But once that is done, downstream users can fine-tune it or do transfer learning with it to adapt it to their particular task — and this fine-tuning is a far more manageable thing to do.
AtmoRep (Lessig et al., 2023) is the first step towards a general-purpose representation model for weather and atmospheric data.
Here’s a clear use-case of such a tool: we now have a wide-range of ML models for Numerical Weather Prediction (NWP), as detailed here, which can rapidly produce forecasts. Many are open-source too. Downstream users, such as businesses, are looking to use the weather predictions from these ML NWP as input features for downstream prediction tasks. How should they do this? One option is to just train an in-house ML model from scratch to do this downstream task. But based on the impact of representation learning for text, a better option may be to first use a general-purpose weather representation model to digest predicted weather states and extract useful mathematical representations, and then train an in-house ML model to fine-tune these. This latter option would be far quicker, less costly and probably easier to do, since the representation extraction task has already been done, so the in-house ML model has fewer things it needs to learn.
I will first give a brief overview of BERT (Devlin et al., 2018), a popular representation model for text, since its training process has inspired other representation learning models, including AtmoRep. I’ll also bring up a key paper in representation learning for images: Masked Autoencoders are Scalable Vision Learners (He et al., 2021). Then I’ll cover what I find are the key aspects of AtmoRep. Finally, I’ll write about some future directions which I think are exciting.
Language representation learning with BERT
In 2018, the BERT model was used to improve Google search. Here’s one of their examples:
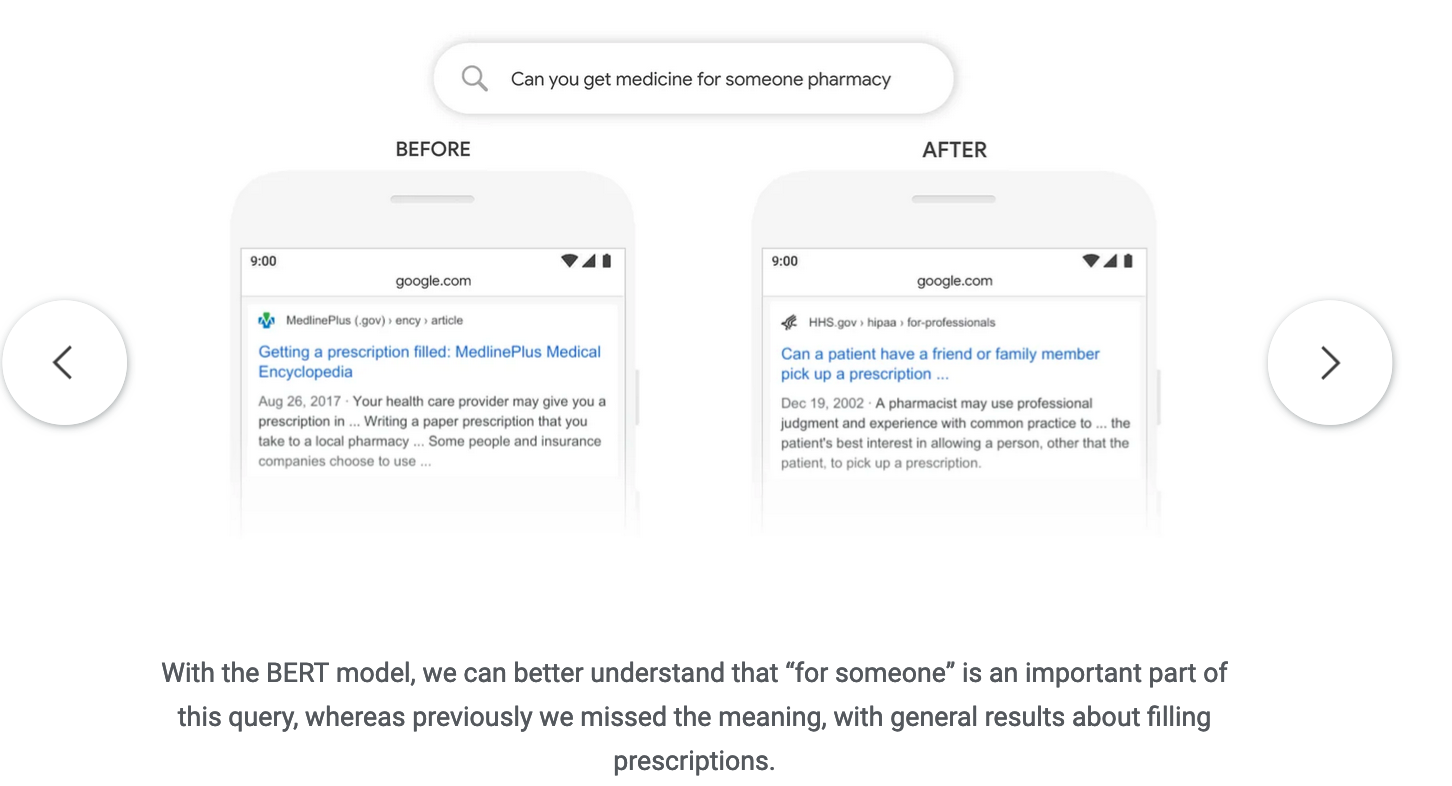
With BERT, the inherent meaning of the search query is able to be better extracted. BERT is good at extracting meaningful representations from text.
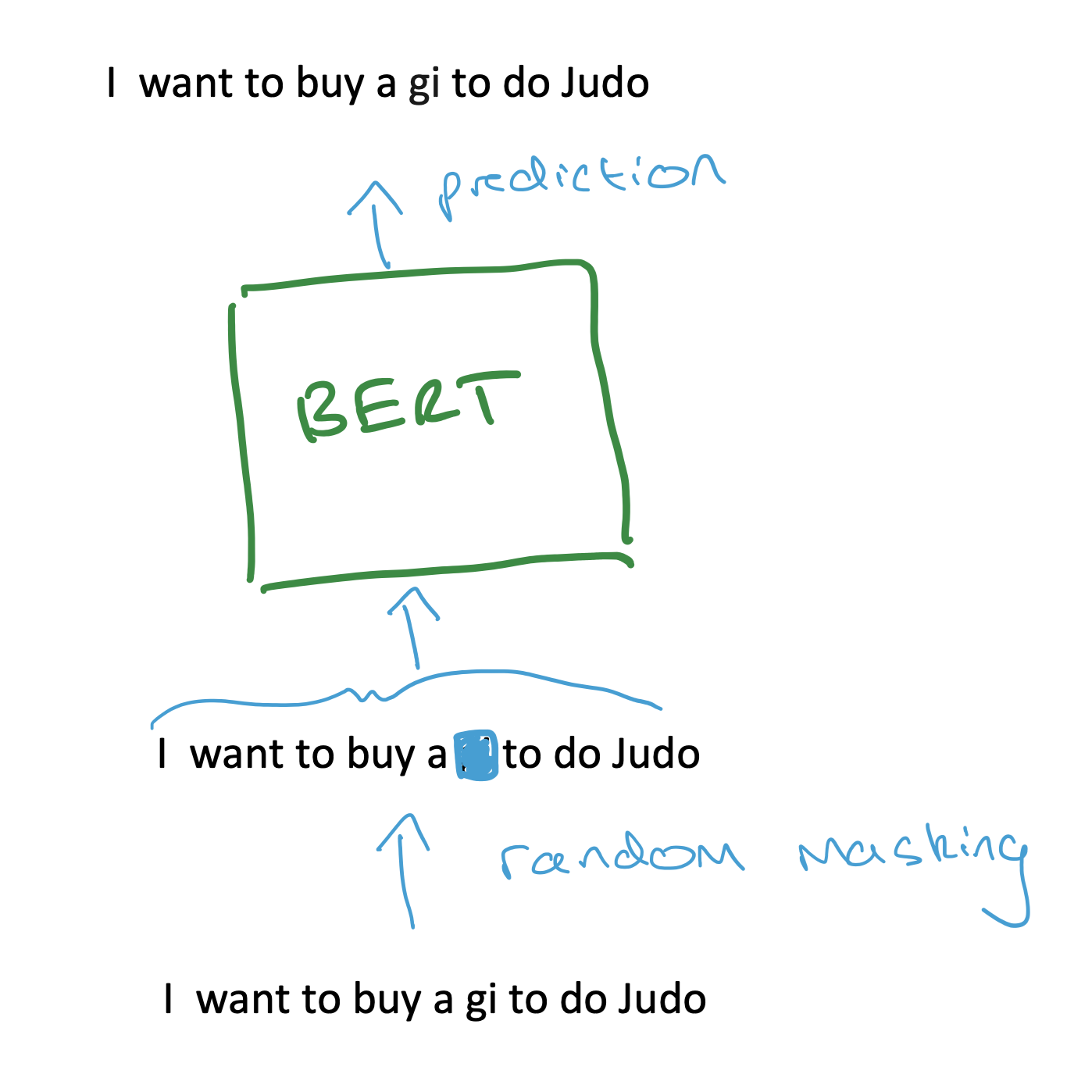
One of the key things responsible for BERT’s abilities is the “masked language modelling” training strategy. In Figure 2, I show a schematic of it. We take a sentence, hide (“mask”) around 15% of the words, and pass this sentence along with the masked words into BERT. We then train BERT to predict what these masked words actually are. BERT itself consists of Transformer layers which are used to look at the input sentence and to use the unmasked words to infer what the masked words are.
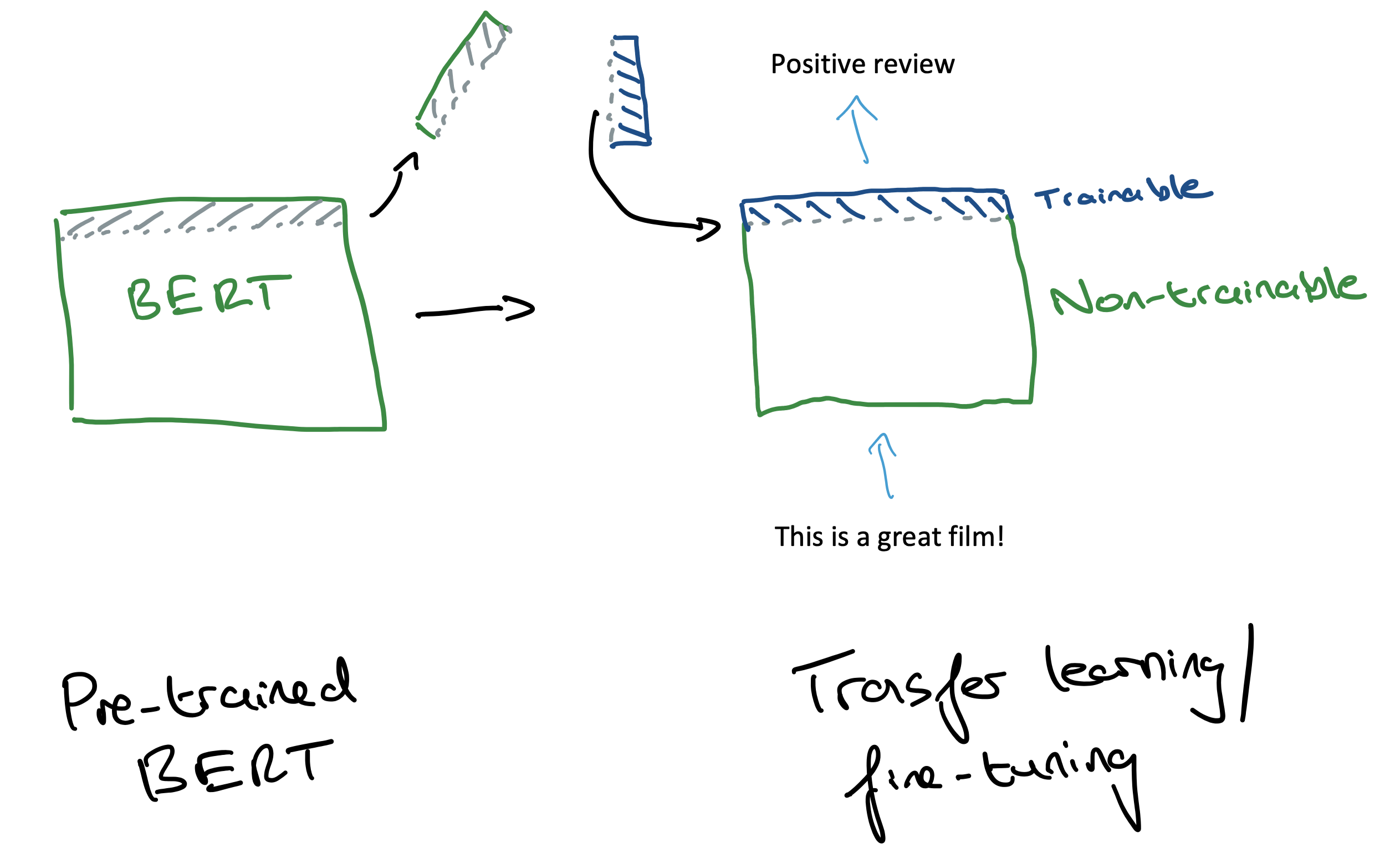
And when it comes to downstream tasks, we can take BERT, remove its last few layers, and add some new layers (Figure 3). We can then fine-tune these new layers to do our specific task, such as sentiment analysis.
Why BERT-style masking may work and when it may not
It is somewhat surprising (to me at least) that this masking training process is so effective in learning how to devise useful representations. I don’t think we know exactly what makes it work so well. One intuitive explanation which I read in “Masked Autoencoders are Scalable Vision Learners” (henceforth MAE) is that masked training works so well because language is so information-dense. Therefore, training a model to predict a few missing words in a sentence forces it to develop sufficient language understanding. For example, in Figure 2, if we were to try to predict the masked word “gi” ourselves, we would need to look at the whole sentence and rely on our general understanding of language to figure out what makes sense. Therefore, maybe a ML model must learn to do the same.
However, if we move away from text to images, the same masking procedure may not be appropriate. If we were to mask out 15% of an image, we may still be able to predict the masked parts simply by looking at their unmasked neighbours and interpolating (Figure 4). Sophisticated high-level understanding of what is going on in the image would not be necessary. This contrasts with the case for language! He et al. discuss this and address the issue by simply masking far more of the training images. In Figure 5, they mask 80% of the images, and train their model to recover the masked parts. This is supposed to force the model to learn more high-level features — no longer is interpolation a viable strategy to solve the task — and it is a key part of their representation learning method for images.


AtmoRep
AtmoRep uses a masked training procedure, illustrated in Figure 6. It is trained by taking a spatially local set (instead of the full global data, for efficiency reasons) of weather fields (e.g. temperature, humidity) across a certain time-window, masking out parts of these fields at different points in space and time, and then training a model to recover the masked values.
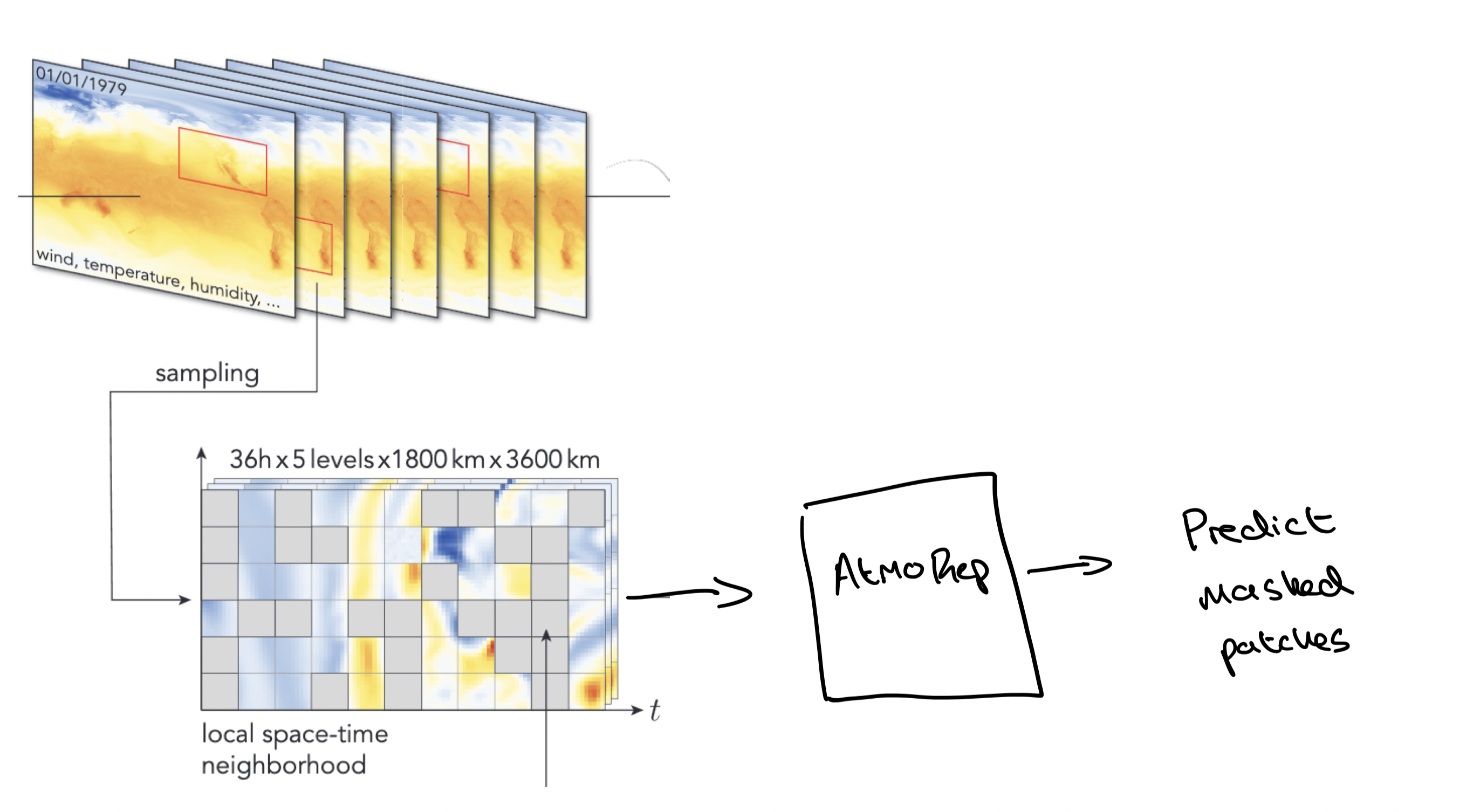
The model itself is based on Transformer layers. One of the nice contributions in AtmoRep is a modular design: separate Transformer layers are used for separate physical fields, and these are then coupled together using cross-attention. This means that we can do field-specific pre-training of these layers, and then couple them together for a final training phase. This is shown to speed up overall training since it is less costly than doing the whole coupled training from scratch. In addition, the model is trained to output samples from a probability distribution, but I won’t go into this any further here as I’ll be focussing on the representation learning theme.
AtmoRep is shown to do two types of tasks. The first one follows closely from the masked training objective. Input data is passed in, along with some unknown (masked) quantities which are then predicted. One example task is temporal interpolation, where atmospheric data at a given temporal resolution can be recast to a higher temporal resolution. Since AtmoRep is trained on hourly data, an atmospheric dataset at, say, 3hr resolution can be passed into the AtmoRep model with the intermediary hourly time-steps passed in as masked patches. AtmoRep can then be used to fill in these hourly gaps, thereby doing temporal interpolation.
The second type of task is an extension of the first. AtmoRep is used to create some outputs (e.g. gridded atmospheric variables), and these are then fed as inputs into a separate model which is trained to perform a task such as downscaling.
As a side note, there is a link between models like AtmoRep which use masked training procedures and models from the Neural Process family. Neural Process models like the Transformer Neural Process (Nguyen et al., 2022) and Taylorformer (Nivron et al., 2023) use a similar masking procedure in training to encourage learning a property called “consistency” (which I won’t go into here). Given the benefit of the masked training procedure for representation learning, there seems to be a link between learning “consistent” processes and learning good representations.
Future directions
Using AtmoRep in a BERT-like manner
Once BERT has been trained, downstream users just need to replace the last few layers and fine-tune these on their task. This contrasts with how AtmoRep is currently used in the paper: the current results seem to be for tasks where the actual outputs of the base AtmoRep model are used (either directly, or indirectly by being fed into another network). Whilst it is great that it can perform such a wide range of tasks, I think to really tap into the power of representation learning for atmospheric dynamics, we should see where the BERT protocol takes us — let’s take AtmoRep, replace its final layers, and then fine-tune these new layers on a specific task of interest.
For example, in hydrology, flood forecasting is a common task. ML has been deployed here with the goal of predicting streamflow (volume of water that moves over a specified point, per unit of time). Some of the input features into an ML hydrology model are forecasted weather states, such as 2 metre temperature and total precipitation. Currently, these are directly fed into the ML hydrology model. But instead, it may be beneficial to first pass these weather states into AtmoRep, and then use the last hidden layer (which has hopefully learnt some useful representation) as input into the hydrology model.
Representation learning for different types of weather data
The downstream user may wish to feed in recent observational data as input to their models, along with forecasted weather states (whether they be forecasted by ML or traditional means). NWP forecasts are made based on an initial weather condition, and this initial condition is created (using a process called “data assimilation”) from recent observational data. Data assimilation is quite costly, so it can take a few hours for new initial conditions to become available for use in forecasts. Now, a downstream user may have observational data from after the data assimilation was performed (i.e. more up-to-date observational data), or they may have access to local observational data sources that centres like the ECMWF do not have when doing data assimilation. And this downstream user may wish to use this observational data in their model.
Figuring out how representation learning should be done for these data sources is an open question. Will we have a general-purpose model to extract representations from both gridded forecasts and un-gridded observations, or will we employ separate models?
What training strategy encourages useful representations?
Similar to the discussion here on MAE, in AtmoRep the masking ratio was increased (to between 0.5 and 0.9) compared to BERT to encourage learning better representations. I suspect there are various ways we can mask atmospheric data to encourage the learning of useful representations.
Here is one candidate: mask all of a given field (e.g. all temperature values at a given vertical level) and train the model to reproduce this, given data from the other fields (Figure 7). This would force the model to learn good inter-variable representations.

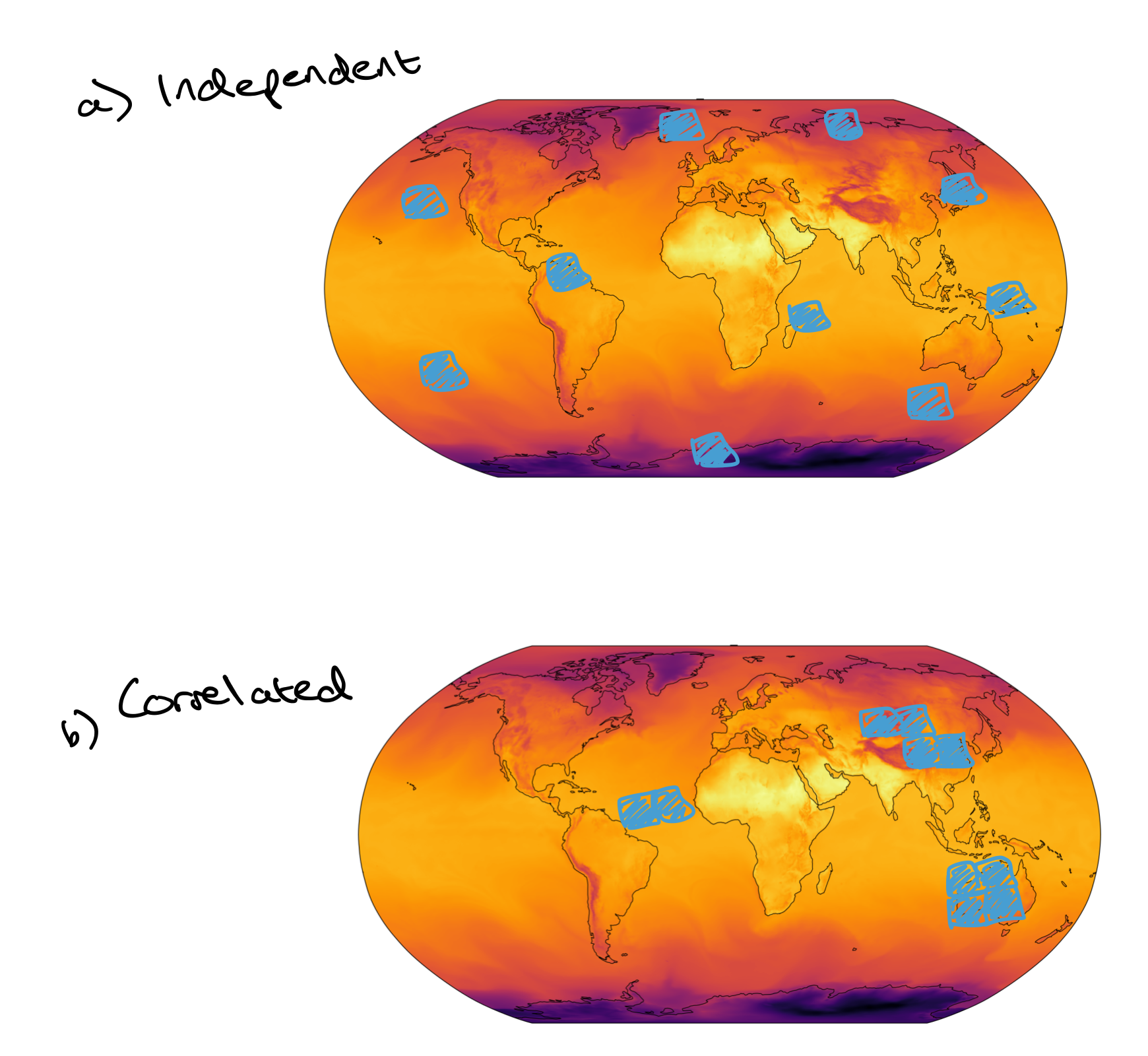
Another candidate: instead of independently sampling which patches to mask, sample in a correlated fashion such that if a patch is chosen to be masked, it is more likely that neighboring patches will be too (Figure 8). This will make it harder for a model to just rely on interpolation since there will be huge chunks of the field missing. And so this may encourage better representations to be learnt.
Scaling up to more data
It is for efficiency reasons that AtmoRep uses a local, not global, space-time window. As discussed here, the “attention” operation is expensive for larger data. One approach which could address this, again from He et al., is to train a masked autoencoder with an asymmetric encoder-decoder design. As shown in Figure 9, a large encoder can be trained to map only the unmasked patches to a latent representation. A high masking ratio significantly reduces the number of patches which are passed into the encoder, thereby reducing computational cost. The encoder is what is responsible for learning the useful representations, so the reduction in computational cost due to fewer input patches allows us to scale up the encoder and make it more powerful.
A lightweight decoder can then be used to process the latent representations and the masked patches, and reconstruct the image.
For downstream tasks, the decoder is scrapped, and extra layers can be appended to the end of the encoder in order to fine-tune for specific tasks.

Conclusion
Representation learning has been key to ML for text and images. I suspect it may also be very useful to the weather and atmospheric domain. AtmoRep is the first step here. Using it in a BERT-like manner may help us get more use out of its representations. And thinking about alternative masking procedures may help us get better representations.
Citation
Cited as:
Parthipan, Raghul. (April 2024). Representation learning for weather data. https://raghulparthipan.com/posts/2024-04-19-representation-learning-for-weather/.
Or
@article{parthipan2024representationlearning,
title = "Representation learning for weather data,
author = "Parthipan, Raghul",
journal = "Raghul Parthipan",
year = "2024",
month = "April",
url = "https://raghulparthipan.com/posts/2024-04-19-representation-learning-for-weather/"
}